Problem Statement
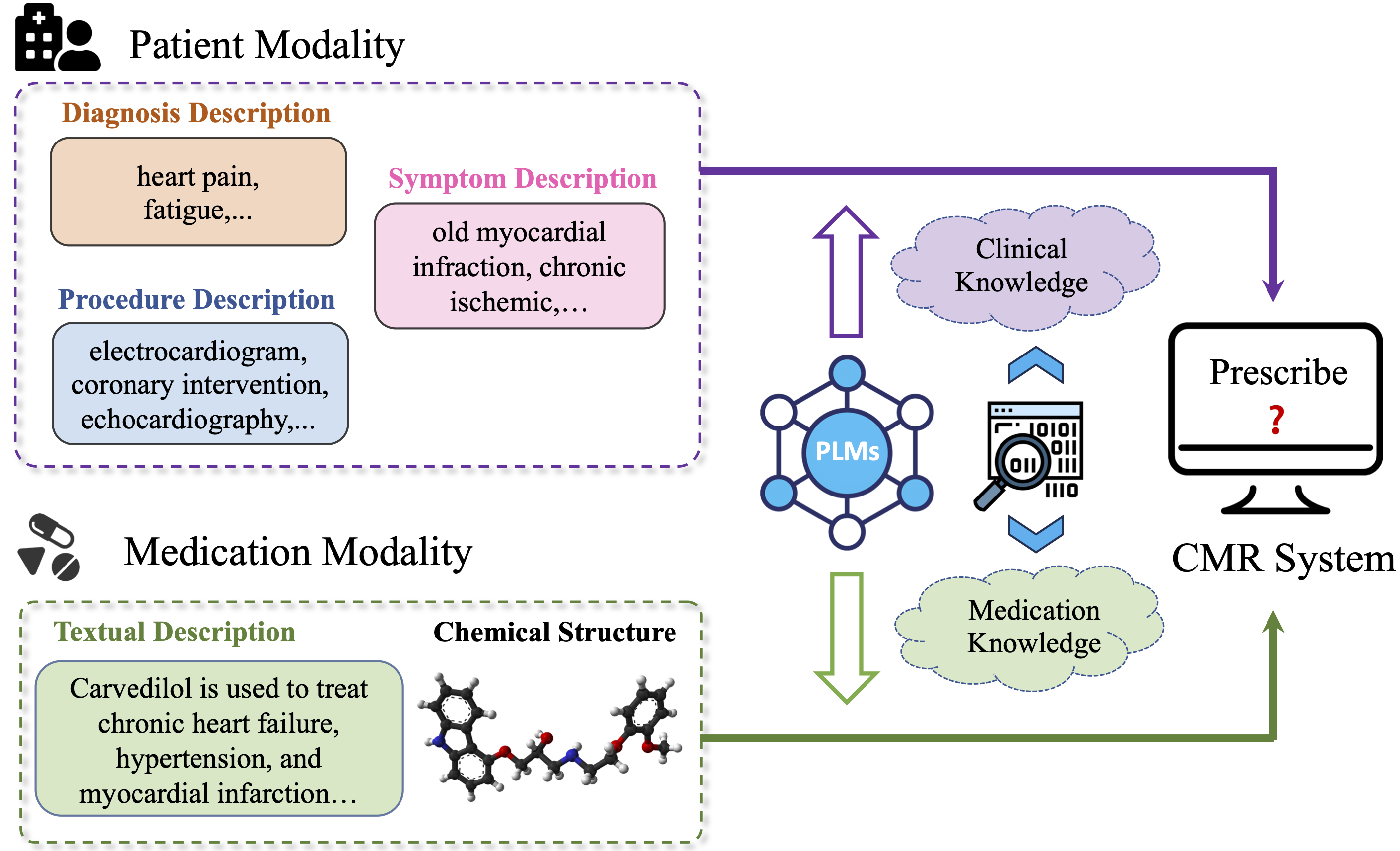
Illustration of combinatorial medication recommendation with help of knowledge extraction from PLMs.
Combinatorial medication recommendation (CMR) is a fundamental task of healthcare, which offers opportunities for clinical physicians to provide more precise prescriptions for patients with intricate health conditions, particularly in the scenarios of long-term medical care. Previous research efforts have sought to extract meaningful information from electronic health records (EHRs) to facilitate combinatorial medication recommendations. Existing learning-based approaches further consider the chemical structures of medications, but ignore the textual medication descriptions in which the functionalities are clearly described. Furthermore, the textual knowledge derived from the EHRs of patients remains largely underutilized. To address these issues, we introduce the Natural Language-Assisted Multi-modal Medication Recommendation (NLAMMR), a multi-modal alignment framework designed to learn knowledge from the patient view and medication view jointly. Specifically, NLAMMR formulates CMR as an alignment problem from patient and medication modalities. In this vein, we employ pretrained language models (PLMs) to extract in-domain knowledge regarding patients and medications, serving as the foundational representation for both modalities. In the medication modality, we exploit both chemical structures and textual descriptions to create medication representations. In the patient modality, we generate the patient representations based on textual descriptions of diagnosis, procedure, and symptom. Extensive experiments conducted on three publicly accessible datasets demonstrate that NLAMMR achieves new state-of-the-art performance, with a notable average improvement of 4.72% in Jaccard score. Our source code is publicly available on https://github.com/jtan1102/NLA-MMR_CIKM_2024.
Illustration of combinatorial medication recommendation with help of knowledge extraction from PLMs.
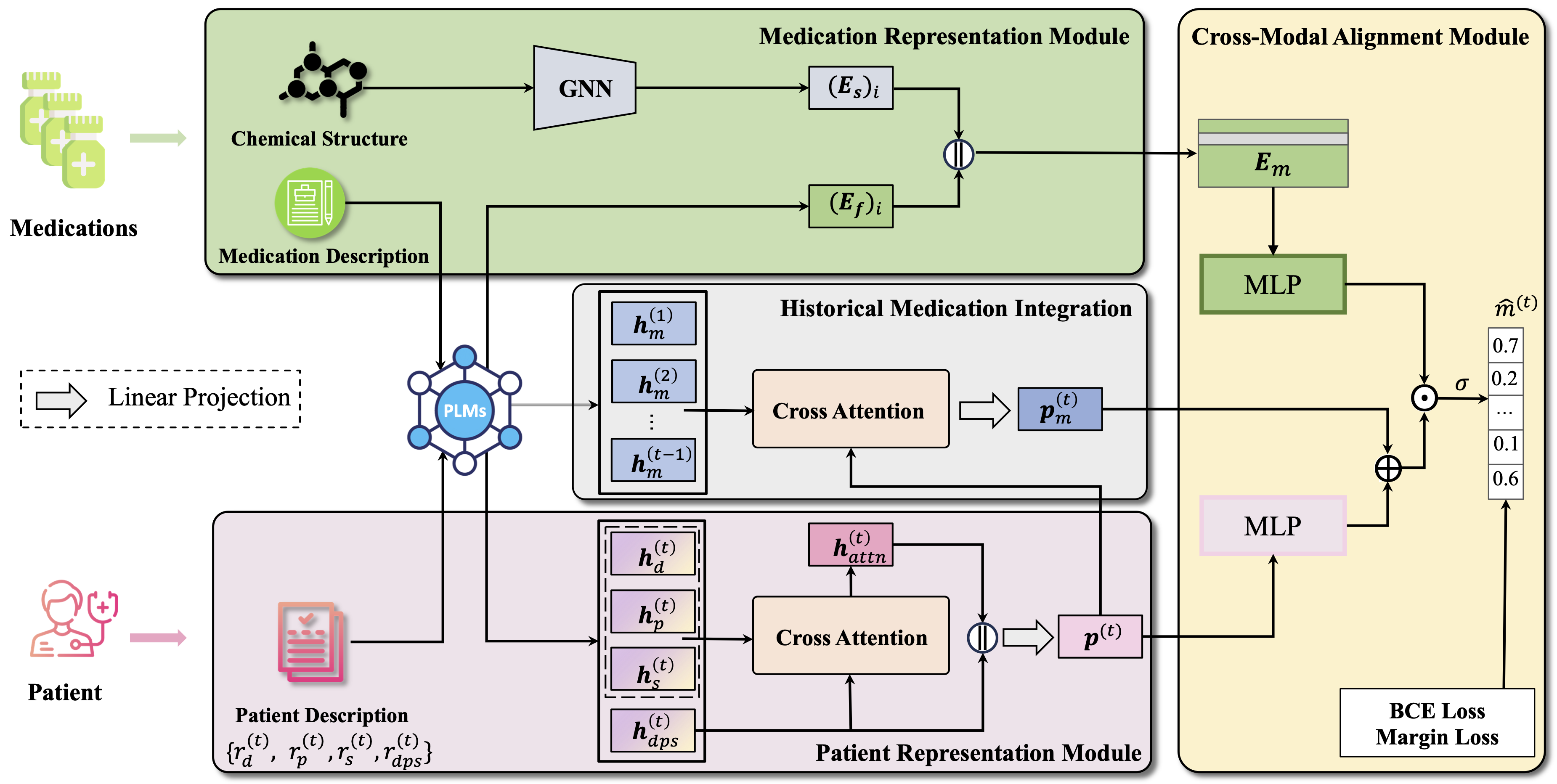
The architecture of NLA-MMR. NLA-MMR is composed of three modules: (a) Patient Representation Module employs PLMs as the base encoder to construct the representation of patient modality from the diagnosis, procedure, and symptom. (b) Medication Representation Module incorporates the embedding derived from textual medication descriptions and chemical structures to build the representation of medication modality. (c) Cross-Modal Alignment Module takes the representation from patient and medication modality as input and aligns them in the same latent space. We further consider historical medication usage information to model the patient’s clinical history, which can enhance the representation of patient modality.
@inproceedings{DBLP:conf/cikm/TanRZBXH0M24,
author = {Jie Tan and
Yu Rong and
Kangfei Zhao and
Tian Bian and
Tingyang Xu and
Junzhou Huang and
Hong Cheng and
Helen Meng},
editor = {Edoardo Serra and
Francesca Spezzano},
title = {Natural Language-Assisted Multi-modal Medication Recommendation},
booktitle = {Proceedings of the 33rd {ACM} International Conference on Information
and Knowledge Management, {CIKM} 2024, Boise, ID, USA, October 21-25,
2024},
pages = {2200--2209},
publisher = {{ACM}},
year = {2024},
url = {https://doi.org/10.1145/3627673.3679529},
doi = {10.1145/3627673.3679529},
timestamp = {Sat, 30 Nov 2024 21:10:26 +0100},
biburl = {https://dblp.org/rec/conf/cikm/TanRZBXH0M24.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}